abstract 요약
belief map, 즉 confidence map에 동작시키는 convolutional networks를 기존의 구조(pose machine)에서 추가하였고, 이로 인해 각 part 좌표를 탐지하는 성능이 좋아졌다고 한다.
또한 기울기 소멸 문제에 대해 설명하는데 중간 지도자의 역할을 하는 natural learning objective function을 제공함으로 써 기울기 소멸문제를 해결했는데 이에 대한 설명이 주를 이룰 것으로 보인다.
정리하기 전에 일단 이해한 내용들 적어놓기
1. 찾기 쉬운 영역을 찾고 그 part가 제공하는 spatial context으로 인해서 찾기 어려운 part를 쉽게 찾을 수 있게된다.
예) 목, 어깨, 머리를 찾으면 ==> 오른쪽 팔꿈치를 찾기 쉬워진다.
2. 신경망에서 receptive fields가 크면 먼 거리에 있는 parts들의 공간적 상호작용도 잘 찾아낸다.
3. 모든 레이어에 대해서, 중간 관리자(intermediate supervision)가 있는 model들은 기울기 소멸문제가 발생하지 않았으나 중간관리자가 없는 모델들은 기울기 소멸문제가 발생하는 것을 볼 수 있었다.
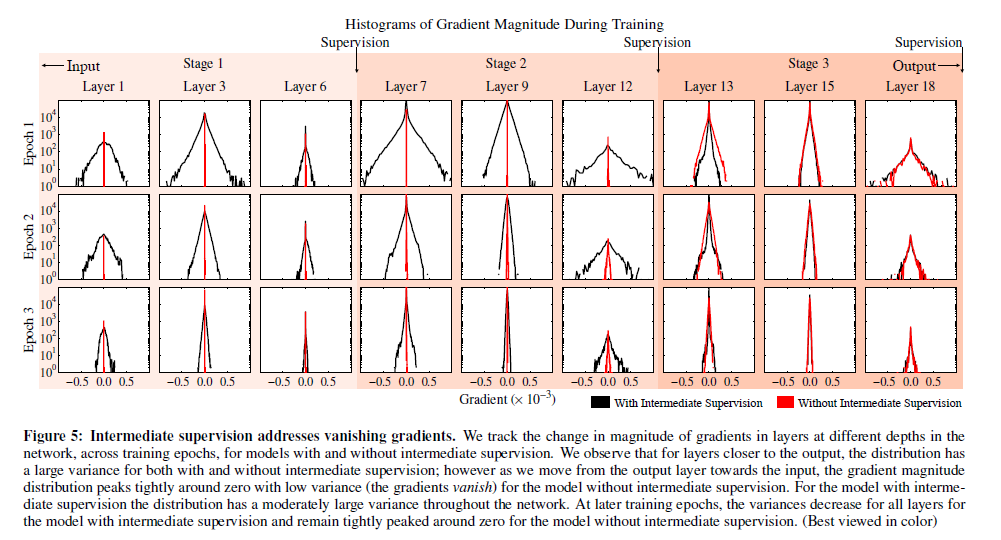
위 사진에는 빨간색 그래프와 검은색 그래프가 같이 있는데, 빨간색 그래프의 폭은 매우 좁거나 0에 가까운 것을 볼 수 있다. 이는 기울기 소멸문제로 학습이 중단된 것을 의미하고, 검은색 그래프처럼 폭이 꽤 넓은것이 기울기가 안정적으로 소멸하는 것으로 제대로 학습이 된것을 의미한다. 위 사진에서도 언급하듯이 빨간색 그래프가 중간관리자(intermediate supervision)이 존재하지 않는 모델이고, 검은색이 존재하는 모델.
4. 한계 : 여러사람이 근접하게 있을 때는 pose estimate에 실패함.
5. pose machine과 구조가 거의 비슷하다.
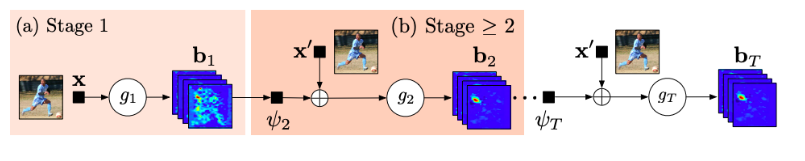
용어설명 :
x : stage1에 들어가는 image feature
x' : stage 2이상에 들어가는 image feature
b : belief maps
psi : belief maps을 더 좋은 특징으로 만들기 위한 function
z : parts의 location pixel
이 구조에서 convolution 개념이 들어가는 곳은?
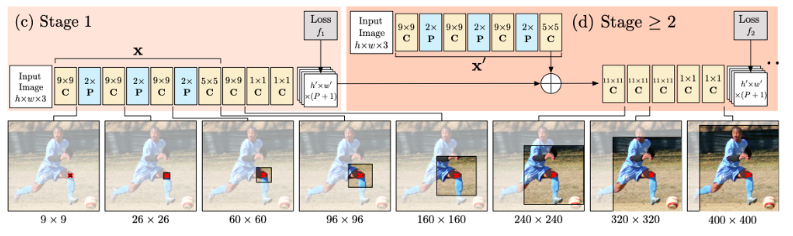
classifiers of stages t(t >= 2)는 이전 단계의 belief maps에 convolution을 적용하고 input으로넣는다. 이 메커니즘은 joints간의 상관관계를 더 잘 이해하게 하고 better predictions에 기여한다. 예를 들어 오른쪽 어깨가 우상단에 있으면 오른쪽 팔뚝이 좌하단에 있을 가능성이 줄어들기 때문에 이를 고려한다는 말이다.
내가 궁금했던것(해결)
1. fully convolution 개념은 이미지 특징들을 잡으면서 정보손실이 오는데 이 때 생기는 정보손실을 최소화 하고자 하는 것이다. 그래서 여기서의 정보손실 최소화가 어디에 작용해서 어떤식으로 도움이 된다는 건지 궁금하다.
정확히 어떤 정보가 사라지는걸 막는건지?
논문 내용에 따르면 context function을 구하는데 convolution을 사용했다고 한다. 즉, belief map을 토대로 주변 맥락정보를 얻는데 있어서 딥러닝의 도움을 얻었다는 건데 이 때, convolution연산 자체는 사람이 특징을 찾는거보다 컴퓨터가 특징잡는것을 더 잘하니까 더 성능이 좋다는것이 확실히 이해가 간다. 그리고 fully convolution연산을 쓴 이유는 이미지특징을 잡아내는 과정에서 정보손실을 최소화하기 위해서로 보인다. 정보손실이 일어나면 이미지가 뭉뚱그려지는데 그러면 stage를 거칠수록 context정보를 얻어내기 힘들기 때문에 fully convolution 개념을 이용한것으로 보인다.
The feature function 𝜓 serves to encode the landscape of the belief maps from the previous stage in a spatial region around the location z of the different parts. For a convolutional pose machine, we do not have an explicit function that computes context features. Instead, we define 𝜓 as being the receptive field of the predictor on the beliefs from the previous stage.
표현을 보면 𝜓 함수는 belief map을 토대로 context feature를 뽑아내는 과정인데 그 과정에서 convolution 연산을 하는 것을 알 수 있다. 3.2.1 내용을 보면 human skeleton 모양상 머리나 목, 어깨같은 부위의 위치를 알면 팔뚝의 위치가 대략적으로 어디있을지 예측하는데 도움을 준다고 한다. 이런 human skeleton의 correlation을 이용하는데 있어서 conv연산을 사용하니 context 관계를 알아내는 것이 기존에 본 연구자들이 contexture function을 직접 만든것보다 좋았다고 한다. 그러나 deep learning의 특성상 function의 내용을 알기는 어렵다고 한다.



