이전까지는 graphical models에 근간하여 사람의 pose estimator를 만들었으나 카네기멜론에서 제안하는 새로운 방식은 이전의 방식에서 벗어나 새로운 method를 제안한다.
Introduction
사람 관절 추정의 어려움, 기존 모델 설명, 이 논문에서 사용하는 모델의 특징 간단 소개
사람의 관절 추정이 어려운 가장 큰 두가지 이유는 다음과 같다.
- 사람 관절의 자유도가 높다. 거의 20자유도 가까이 된다.
- 이미지에 찍힌 사람에 대한 변수가 많다.(사람의 자세, 이미지의 상태 등)
기존의 graphical model의 단점은 간단히 말하자면 데이터의 complexity와 tractability of inference의 관계가 trade off 관계라는 것이다.
사람이 다양한 자세를 취하더라도 자세를 추정하려면 사람이 복잡한자세(이를테면 self-occlusion의 상태)에 있더라도 keypoint에 대한 inference가 나와야 하는데 그렇지 못하다는것. 즉, 자세가 간단하면 관절추적상태가 좋고, 자세가 복잡하면 관절추적상태가 좋지 못하다는 것이다.
따라서 이 논문에서는 이런 trade-off관계에 있는 문제점을 피하고자 graphical 한 방식의 pose estimation이 아닌 다른 method를 활용하기로 하였다.
논문의 써있는 말을 그대로 가져오면
Our approach avoids this complexity vs. tractability trade-off by directly training the inference procedure.
즉, 추론과정을 직접 학습하겠다는 접근법이다.
여기서 소개하는 모델의 구조를 논문의 표현을 인용하자면
Conceptually, the presented method, which we refer to as a Pose Machine, is a sequential prediction algorithm that emulates the mechanics of message passing to predict a con dence for each variable (part), iteratively improving its estimates in each stage.
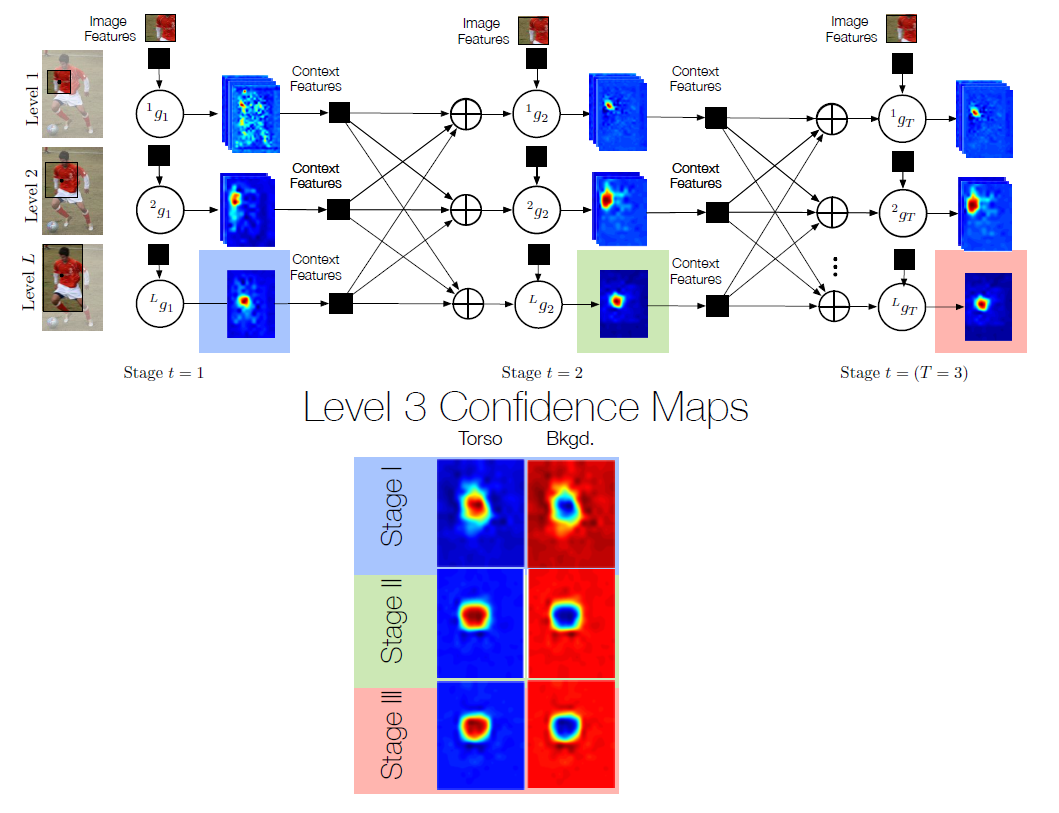
간단히 말하자면 일련의 간단한 classifier들의 집합이고 이 구조가 stage단계, level단계로 점진적으로 학습해 나가는 단계이다. 이 논문에서 말하고자 하는 것이 바로 이 구조의 개념과 각 단계에서 하는 역할이므로 밑에서 천천히 소개하도록 하겠다.
본 논문에 대한 개략적인 설명

위의 논문인용부분은 다음과 같은 구조를 말한다.
기존의 structed prediction 문제를 sequence of simple classification problem, 즉 연속된 subproblem으로 간략화 시켰다고 볼 수 있고, 이것은 나의 견해가 아니라 논문에서 나온 표현이다.
위 사진의 분류기는 딥러닝의 분류망과 흡사한 기능을 하고있어 다음에 리뷰할 convolution pose machine에서는 CNN개념을 사용한 인공신경망으로 대체될 예정이다.
이 논문에서 진행한 실행법으로 또 눈여겨 볼것은 receptive field의 크기를 변화시키며 input data를 학습시켰다는 것이다.

level을 거쳐갈 수록 receptive field를 키워가는 것을 볼 수 있는데
한 level안에서는 여러 classifier를 거치며 학습하고 level이 증가함에 따라 탐지영역또한 키워가며 학습을 진행했다.


또한 이 방법은 지도학습법을 통해서 pose estimation문제를 해결한 경우라고 볼 수 있다.

학습을 하면서 계속 Image Features를 제공하기 때문에 일종의 답을 제공하는 지도학습이라고 볼 수 있다.
또한 본 논문에서 제시한 방법에 따르면 망을 거치고 나와서 얻은 confidence map은 context의 일부분 누락이 있더라도 꽤 성능이 잘 나온다고 한다. 아래 사진을 참고하자.

그리고 탐지영역, 한번에 고려하는 맥락의 범위가 클수록 detect하는데 더 쉽다고 한다.
인공신경망분석
이 신경망은 결국에는 g를 학습시키는 것이 목적이다. g란 classifier라고 볼 수 있는데 input으로는 training set of images에 있는 patch에 찍혀있는 image feature와 context feature를 input으로 받고 output으로는 confidence map을 내보내는 녀석이다.

위 사진에서 표시한 부분을 보면 알 수 있다.
그런데 여기서 중요한 것은 각 단계의 첫번째 g. 즉 g1은 첫번째 분류기인 만큼 stage를 거쳐서 나오는 결과물을 받고 있지 않기 때문에 image feature만을 input으로 하고 있다.
이를 논문에서는 다음과 같은 수식으로 표현한다.

수식에서 눈여겨 볼것은 g의 인자로 x만 있다는 것이다. x는 image feature를 의미한다.
아래에서 계속 설명하겠지만 다음 predictor부터는 input으로 x와 context features가 같이 들어간다.
구체적으로 설명해주고 있지 않지만 여기서 training set of images로 쓰고있는 이 dataset은 사람이 만들어서 특징점을 찍은 것으로 보인다.
또한 g는 원래 여러개의 predictor이고 다음과 같이 명명한다

여기서 p는 head, neck, ankle등 각 part를 말하고 따라서 gP는 각 파트를 담당하는 하나의 classifier이다. 그러나 여기서는 g를 여러개 사용하지 않고 하나이지만 여러 개의 part를 예측하는 single multiclass predictor 로써 g라고 쓰기로 했다.
용어설명

single multi-class predictor, predictor라고 불린다. t는 stage의 번호를 말하고 l은 level의 정도를 말한다.

b는 confidence map을 의미하고 t는 stage의 번호를 말한다. b는 predictor의 output이다.
만약 bt에 t가 1이라면 1번째 stage의 predictor를 거치고 나온 confidence map을 의미한다.

feature function을 의미한다. confidence map은 이 feature function에 input으로 들어가고 feature function을 거쳐서 feature context라는 output이 나온다. 여기서 이 feature context와 image feature가 같이 다음 predictor인 g로 들어가게 되는데 이를 논문에서는 다음과 같은 수식으로 표현한다.

여기서 합친다는 표현은 다음과 같은 수식을 쓰기로 했다고 명시했다.

confidence map
heatmap으로 표현한 확률이다. 각 part가 해당하는 위치에 있을 확률을 heatmap으로 표현한 것으로 붉은색일 수록 그 부분이 원하는 part라고 예측하는 것이다. 그림을 통해 이해하도록 하자.

context feature
이 논문에서 처음부터 강조한 것이 있는데, 바로 local하게 part를 estimate하자는 것이 아니라 context하게 estimate하자는 것이다. 그런 만큼 여기서 소개하는 context feature를 찾는 이 과정은 중요하다고 할 수 있다.

context feature는 2가지의 context function으로 context feature를 구하고 그 둘을 합쳐서 다음 predictor의 input으로 넣는 방식으로 신경망을 학습한다.
context function1은 neighboring parts의 confidence에 관한 정보를 다 가지고 있는 벡터이다. 논문에서 제시하는 그림을 보면 2차원 배열과 같은 모양으로 주변정보를 가지고 있는것으로 보인다.

이 context function은 confidence를 input으로 받아 context feature를 output으로 내는데 이 때, context function1에서 나온 결과물을 extracted, vectorized patches 라고 하고 다음의 수식으로 표현한다.

두번째 context function은 Non-maxima surpress 알고리즘을 적용하여 input으로 받는 confidence에서 가장 큰 3가지 확률만 남기고 나머지에는 관심이 없다. confidence map위의 z좌표에 대해서 그림으로 표현하면 다음과 같다.

이 때 위에서와 마찬가지로 confidence를 input으로 받고 context feature를 output으로 낸다.
stacking
인공신경망을 통한 학습의 중점은 predictor인 g를 학습시키는 것이다. 그런데 잘 보면 g에 계속 image feature가 들어가지만 논문에 의하면 이전 stage의 context feature가 들어갈 때 그 context feature는 이전에 학습했던 image feature의 결과물이고 다시말하면 똑같은 image feature를 다시 학습하는 과정이기 때문에 overfitting이 올 확률이 높다고 한다.
말이 어렵다면 그림을 통해서 이해해보도록 하자.

위 그림에 빨간색 화살표로 표시한 것을 보면 이해하기 쉬울것이다. 이전에 학습한 x data를 다시 학습하는 것이기 때문이다. 본 논문에 의하면 overfitting을 피하기 위해 cross-validation과 비슷한 stacking을 적용했다고 하나 논문에서 중심적으로 말하고 싶은 바는 아니기 때문에 이쯤에서 넘어가도록 하겠다.
본 논문에서 제시한 방법의 한계
Discussion을 보면
Occlusion pose을 찾는것이 가장 어려운 문제로 남아있다고 한다. 아래 사진을 통해 한눈에 이해할 수 있다.

그리고 두번째 미해결과제가 남아있다고 했는데 그것은 바로 dataset에 관한 문제이다. 드문 포즈, 기이한 포즈를 하고 있는 사람의 경우에는 dataset이 충분하지 않기 때문에 그 자세에 대해서는 pose estimation이 적절히 이루어지지 못했다고 결론지었다.
'연구 > papers' 카테고리의 다른 글
| [논문정리] (AlexNet) ImageNet Classification with Deep ConvolutionalNeural Networks (0) | 2020.10.01 |
|---|---|
| [ResNet] resenet이 degradation에 robust한 이유 고찰 (0) | 2020.09.09 |
| [CPM 논문 정리] Convolutional Pose Machines (0) | 2020.04.03 |
| [논문 정리] openpose 이해를 위한 개념 간단 정리 (0) | 2020.04.02 |
| [논문정리] Efficient Online Multi-Person 2D Pose Tracking withRecurrent Spatio-Temporal Affinity Fields (0) | 2020.04.01 |



